En el laboratorio de I+D de PRiSE hemos estado trabajando en un sencillo test de rendimiento de directorios virtuales, como primer paso para evaluar si éstos son una opción viable en nuestras infraestructuras tecnológicas.
Un directorio virtual nos ofrece un interfaz LDAP que actúa de intermediario con respecto a otro sistema de información, como una base de datos o otro LDAP. Además, antes de servir al cliente los datos tiene la capacidad de trabajar con ellos por lo que pueden ser adecuados previamente a nuestras necesidades.
El directorio virtual que hemos desarrollado está basado en Perl y utiliza los paquetes Net::LDAP::Server y DBI. El objetivo es ver si al conectar dicho directorio virtual con una base de datos MySQL los tiempos son aceptables o no. Para ello, hemos creado una batería de tests donde se realiza la búsqueda N veces de manera secuencial de una entrada en el directorio. No se trataba de ver el rendimiento ante pruebas de stress sino ver si al menos superaba esta sencilla prueba.
Se ha realizado la siguiente batería de tests:
- 10 búsquedas
- 50 búsquedas
- 100 búsquedas
- 250 búsquedas
- 500 búsquedas
- 750 búsquedas
- 1000 búsquedas
Dicha batería se ha repetido 10 veces para quedarnos con el valor medio y evitar así resultados extraños. Los entornos que han sido probados y las búsquedas realizadas son:
- Búsquedas en un OpenLDAP.
- DN base: dc=test,dc=org
- Scope: base
- Filtro: (objectClass=*)
- Atributo requerido: description
- Búsquedas en un MySQL.
- Sentencia SQL: select ‘dc=test,dc=org’ as dn, ‘dcObject\norganizationalUnit’ as objectClass, ‘test’ as dc, ‘test’ as ou, Test.Desc as description from Tabla where Id=’uno’
- Búsquedas en un directorio virtual que conecta con dicho MySQL.
- DN base: dc=test,dc=org
- Scope: base
- Filtro: (Id=uno)
- Atributo requerido: description
El directorio virtual realizará la búsqueda indicada para el MySQL a la hora de obtener los datos y responder al cliente LDAP.
Los resultados obtenidos son:
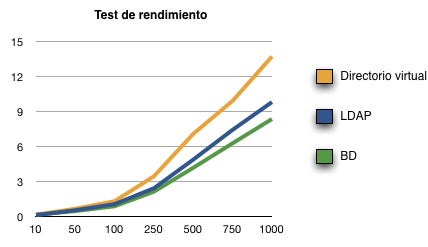
Como podemos ver, a medida que incrementamos el número de búsquedas secuenciales seguidas, el directorio virtual es el más lento de los 3, aunque dicho retraso es bastante aceptable, como veremos más adelante. También podemos ver que el acceso a BD termina siendo más rápido que a un LDAP, y es debido al sistema de caché de MySQL.
Pero veamos los valores, expresados en segundos, que obtuvimos:
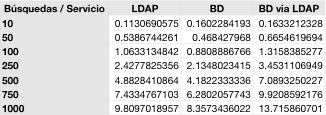
Como podemos ver, al principio (con 10 búsquedas seguidas) el acceso a LDAP es más rápido que el acceso a la BD, ya que todavía el caché de la BD no ha comenzado a funcionar a pleno rendimiento. Además, el directorio virtual se comporta al mismo nivel que la base de datos. A medida que crece el número de peticiones, hay un retraso de un 35% aproximadamente, que gracias a que el tiempo de obtención de los resultados es bajo no va a implicar un coste elevado al integrar nuestras aplicaciones con el directorio virtual.
Tenemos claro que estas pruebas no son definitivas a la hora de evaluar un directorio virtual, pero al menos sabemos que si son cifras que prometen como para seguir trabajando en otro tipo de evaluaciones.
En la comunidad de desarrolladores de PAPI estamos trabajando en la definición del protocolo PAPI v1.1, que traerá algunas mejoras sobre la versión inicial, que ya iremos desvelando poco a poco en este blog.
Una de estas mejoras es la inclusión del parámetro opcional PAPIOPOA en un mensaje ATTREQ, el cual corresponde a una petición de atributos por parte de un PoA o GPoA. Cuando un proveedor de identidad PAPI recibe este tipo de mensaje, en el caso de que el usuario no se hubiese autenticado previamente, necesitará realizar la autenticación del usuario antes de generar la respuesta al GPoA/PoA.
De esta forma, el mensaje ATTREQ queda definido con la siguiente URL:

Mensaje ATTREQ
Donde,
- ATTREQ: contiene el ID del GPoA/PoA que ha realizado la petición.
- PAPIPOAREF: es un valor que establece el emisor del mensaje y que le será devuelto en la respuesta.
- PAPIPOAURL: es la URL del emisor que ha generado la redirección al proveedor de identidad.
- PAPIOPOA: en el caso de que el emisor del mensaje sea un GPoA y haya enviado el mensaje tras recibir solicitud de credenciales por parte de un PoA, este parámetro opcional incluirá la URL de dicho PoA que generó el mensaje al GPoA.
La principal utilidad de PAPIOPOA es facilitar la política de emisión de atributos de los proveedores de identidad. Consideremos el siguiente escenario:
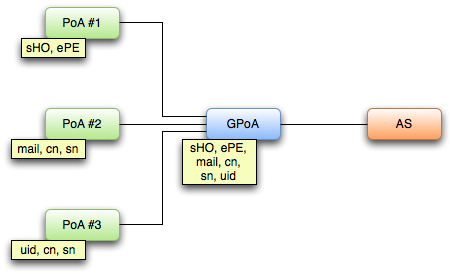
Escenario PAPIOPOA
Como vemos, cada vez que el AS recibe un mensaje ATTREQ emitido por el GPoA, tendrá que emitir todos los atributos que podrían requerir cualquiera de los PoAs que están conectados con dicho GPoA.
Sin embargo, si en el mensaje ATTREQ recibe el parámetro PAPIOPOA, podremos saber cual fue el PoA que hizo la petición al GPoA y emitir sólo los atributos que dicho PoA necesita.
Además, este nuevo parámetro facilita enormemente la generación de unas estadísticas de acceso, ya que sabremos a qué recurso protegido intenta acceder un determinado usuario.
La certificación CDPP promovida por el DPI ya tiene fecha para el primer examen, que se celebrará el sábado 19 de junio. El segundo examen tendrá lugar el 18 de diciembre.
La prueba teórica vendrá definida por:
•150 preguntas con una sola respuesta válida de 4 posibles
•Un caso práctico en el que se harán 20 preguntas con opción Verdadero/Falso.
•Se pasa con un 75% de respuestas correctas.
•No hay puntos negativos.
Será necesario la acreditación de experiéncia dentro de la Privacidad y la Protección de Datos.
Próximamente se publicará el temario y más detalles necesarios para su preparación.
Más información: https://www.ismsforum.es/img/a8/des98_CDPP_-_Certified_Data_Privacy_Professional.pdf
![]()
La Electronic Frontier Foundation (EFF) está trabajando en un interesantísimo proyecto sobre privacidad: Panopticlick. Éste pretende investigar si nuestros navegadores, aun no emitiendo información de IP o a través de cookies, pueden ser fácilmente identificable por terceras aplicaciones web.
La información que proporciona el navegador, como la versión del sistema operativo, los plug-ins que tiene activado, las fuentes o tipos de letra que soporta, proporcionan una huella digital que podría servir para identificar nuestro puesto informático. De hecho, esta técnica se conoce como Device fingerprint y se sabe que es una de las técnicas que utilizan las empresas de publicidad en Internet, a la hora de personalizarnos los anuncios a mostrarnos.
Como vemos, el objetivo de esta investigación es obtener una base de datos anónima de navegadores de cara a saber si es posible o no identificar únicamente nuestro navegador con la información que envía y hasta que punto debería ser corregido este asunto.
Yo he probado con mi navegador Safari 4 y Firefox 3.5 y en ambos me ha informado que con su actual base de datos de más de 420.000 navegadores diferentes, podrían identificarlos unívocamente. Parece que la privacidad en Internet sigue siendo algo por lo que luchar, ¿no?