A continuación compartimos un interesante video (en inglés) sobre cómo funciona la criptografía asimétrica (de clave pública) explicada con colores. El algoritmo matemático utilizado en el video es Diffie-Hellman.
Este método criptográfico es utilizado en numerosos sistemas, como los basados en certificados o los que utilizan infraestructuras de clave pública (PKI).
Al principio de la era digital, las personas hacían uso de sistemas básicos de autenticación para poder acceder a recursos: si querían acceder al correo de la facultad o acceder a tus datos de matrícula necesitabas tener en tu poder un nombre de usuario y una contraseña específica para ello.
La cosa comenzó a complicarse cuando se vio la necesidad de que profesores subieran documentos e información con acceso restringido a los sistemas de la universidad. Para permitir este acceso comenzaron a necesitarse unas credenciales específicas. Además, la universidad comenzó a ofrecer más y más servicios, usando las credenciales originales u otras nuevas, dependiendo de la aplicación que se utilizara, acabándose por tener una organización con un conglomerado de fuentes de datos, aplicaciones y protocolos heterogéneas e incomunicadas entre ellas.
Para solventar el problema de desorganización, seguridad y eficiencia se ha comenzado a implantar sistemas que unifiquen la gestión de la identidad de las organizaciones mediante proveedores de identidad como adAS o directorios virtuales que concentran la entrada a fuentes de datos como VirDAP.
Hasta este punto, el problema era poder autenticar a los usuarios de nuestra organización en un sólo punto (Single Sign-On); pero una vez resuelto este asunto comienzan a plantearse otras implicaciones: ¿Qué ocurre con los usuarios que no son de mi organización y que quiero que accedan a mi sistema, por ejemplo: usuarios de selectividad, estudiantes extranjeros o de otras universidades?
Para solucionar este aspecto se pensó en la creación de Federaciones, donde universidades y otras organizaciones crean acuerdos entre ellas que permiten que usuarios de unas y otras puedan acceder a los recursos de ambas. Los inconvenientes de una solución federada son importantes, tanto burocráticos como tecnológicos, ya que implican firma de convenios, entrega de información personal de los usuarios, implantación de un sistema común a los integrantes de la federación y el coste (material, tiempo, personal de mantenimiento) que esto suponte, etc.
Quizás es hora de mirar un poco más allá y pensar en una solución diferente, la denominada Autenticación Delegada: ¿Por qué no dejar que los sistemas de cada organización traten con sus propios datos? En un sistema de autenticación delegada se trata la información de la siguiente forma:
- Un usuario quiere acceder a un recurso de la organización X
- Para ello accede a la página de control de acceso de su organización X
- En ella se le permitirle autenticarse con su organización Y, se le redirige al control de acceso de su organización
- El usuario se autentica en Y
- Y responde a X diciéndole si el usuario está autenticado o no
- Y deja acceder al usuario en consecuencia de la respuesta anterior.
Esta solución permite evitar a ambas organizaciones tener que haber implementado una federación y con la mera integración de los Single Sign-On de ambas es posible la autenticación delegada, sin traspaso de más información personal de los usuarios que la imprescindible, evitando la creación de cuentas duplicadas y eliminado la necesidad de que el usuario tenga que aprenderse/utilizar otro tipo de credenciales más.
Y ahora bien, nos queda el problema de decidir de qué organizaciones nos fiamos más o menos, por ejemplo, si un alumno de la universidad quiere cambiar sus datos bancarios, ¿nos fiamos de cualquier autenticación delegada? Incluso dentro de nuestra propia organización puede que querramos utilizar certificados o DNIe en vez de usuario y contraseña para ciertos trámites. La pregunta que nos queda es ¿Cuáles son los sistemas más confiables? ¿Qué orden de confianza le doy a mis sistemas de autenticación, tanto local como delegada?
Para responder a esta pregunta habrá que implantar lo que se denominan Niveles de Confianza (LoA, Level of Assurance). De ellos ya hablaremos en posteriores entradas del blog.
Continuará ![]()
![]()
La Electronic Frontier Foundation (EFF) está trabajando en un interesantísimo proyecto sobre privacidad: Panopticlick. Éste pretende investigar si nuestros navegadores, aun no emitiendo información de IP o a través de cookies, pueden ser fácilmente identificable por terceras aplicaciones web.
La información que proporciona el navegador, como la versión del sistema operativo, los plug-ins que tiene activado, las fuentes o tipos de letra que soporta, proporcionan una huella digital que podría servir para identificar nuestro puesto informático. De hecho, esta técnica se conoce como Device fingerprint y se sabe que es una de las técnicas que utilizan las empresas de publicidad en Internet, a la hora de personalizarnos los anuncios a mostrarnos.
Como vemos, el objetivo de esta investigación es obtener una base de datos anónima de navegadores de cara a saber si es posible o no identificar únicamente nuestro navegador con la información que envía y hasta que punto debería ser corregido este asunto.
Yo he probado con mi navegador Safari 4 y Firefox 3.5 y en ambos me ha informado que con su actual base de datos de más de 420.000 navegadores diferentes, podrían identificarlos unívocamente. Parece que la privacidad en Internet sigue siendo algo por lo que luchar, ¿no?
Últimamente me he visto envuelto en diferentes debates sobre si era seguro o no usar certificados con capacidades SSL, no sólo para asegurar conexiones TCP y/o autenticar servidores, sino también para firmar metadatos o aserciones.
El escenario en el que nos encontramos es el indicado en la figura, en el cual un cliente realiza conexiones HTTPS contra un IdP (Proveedor de Identidad) para acceder a un sistema SSO y por ende a recursos protegidos. Dónde al logarse el cliente con éxito, el IdP genera una aserción sobre quién es el cliente y qué atributos posee, el IdP firma esta aserción con el mismo certificado que se ha usado para establecer la conexión HTTPS.
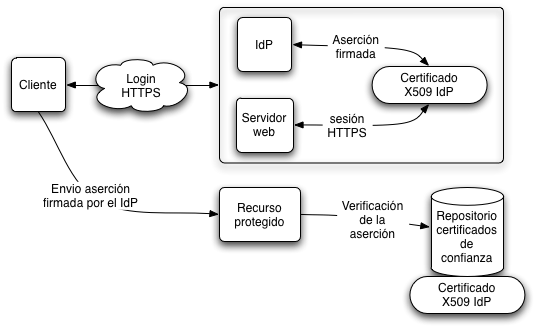
Escenario
El problema, o mejor dicho, el origen de las inquietudes reside en el uso del mismo certificado para la conexión HTTPS y para la firma de la aserción o de cualquier otro tipo de metadatos, y en el cual confían los SPs (proveedor de servicio) que han establecido relaciones de confianza con el IdP.
Pues bien, estas inquietudes se basan en la creencia incierta de que un servidor web firmará alegremente cualquier cosa presentada por el cliente en el ‘random binary blob‘ durante el SSL-handshake. Si esto fuese cierto un atacante tendría la capacidad de enviar como ‘random binary blob‘ una aserción falsa, que al ser firmada por el certificado x509 en el que confían los SPs, le diese la capacidad de acceder a recursos a los cuales no tiene acceso.
Esto es totalmente falso, ya que bajo ninguna circunstancia un servidor web firmará datos arbitrarios presentados por un cliente. Para aclarar esto voy a explicar que datos presenta el cliente al servidor y que son susceptibles de ser firmados.
Durante el handshake del protocolo TLS/SSL se genera el master secret, el cual es un secreto compartido entre el cliente y el servidor, de 48 bytes y que es usado como clave simétrica para proteger la sesión. Este master secret, se genera mediante la siguiente función:
master_secret = PRF(pre_master_secret, "master secret",
ClientHello.random + ServerHello.random);
Donde PRF es la Pseudoroandom Function elegida de la cipher-suite- especificada en fases previas del handshake, la cual es una función basada en HMAC, que no usa en ningún momento la clave privada del certificado.
El pre_master_secret, es una cadena de 48 bytes enviada por el cliente al servidor y que es lo que nos interesa en este caso, ya que representa los únicos datos que el servidor cifra de forma «alegre».
La cadena «master secret» es una constante con dicho valor.
Y por último las cadenas ClientHello.random y ServerHello.random son dos blob de 28 bytes, el primero enviado por el cliente en la fase ClientHello del handshake y el segundo enviado por el servidor en la fase ServerHello.
Como he dicho anteriormente, nos interesa el pre_master_secret, ya que esta cadena son 48 bytes, de los cuales 46 son generados aleatoriamente por el cliente y 2 indican el protocolo. Estos 48 bytes son cifrados con la clave pública del servidor. Y es este cifrado el punto que ha generado tanta controversia.
Pues bien, al cifrarse estos datos con la clave pública del servidor, es este servidor el único que puede descifrar y por tanto entender estos datos, ya que es el único en posesión de la clave privada correspondiente.
Con esto, si un cliente malintencionado en vez de generar 46 bytes aleatorios, introduce la aserción falsa, lo que obtendría es un mensaje cifrado que sólo puede leer quien posea la clave privada del servidor. La cual no está en posesión de los SPs, ya que estos sólo necesitan la clave pública, para comprobar la firma de las aserciones.
Como conclusión, decir que podemos estar seguros de usar el mismo certificado x509 tanto para asegurar sesiones con TLS/SSL como para firmar aserciones o metadatos ya que según la especificación del protocolo TLS los datos que un servidor cifra «alegremente», sólo los puede descifrar él.
Por último decir que separar por roles el uso de claves privadas de los certificados x509, es decir, usar una para TLS y otra para firmar aserciones y/o metadatos, es una buena práctica de seguridad. Ya que aunque TLS ha sido diseñado para resistir ataques contra autenticación y firmado, la historia nos ha demostrado muchas veces que confiar en la calidad de un algoritmo o protocolo y en su implementación debería evitarse en la medida de lo posible.